Наскоро в работата си в TRANSACT Дания, специалисти забелязват няколко големи уебсайта, „ударени“ от спам данни в Google Search Console и решават да споделят казуса – как правилно настроеният robots.txt предотвратява превръщането му в проблем.
Откритието води до паника
Обикновено се случва някой да открие че Google Search Console докладва огромен наплив от „лоши“ URL адреси, които (ако robots.txt е настроен правилно) са посочени като блокирани от robots.txt.
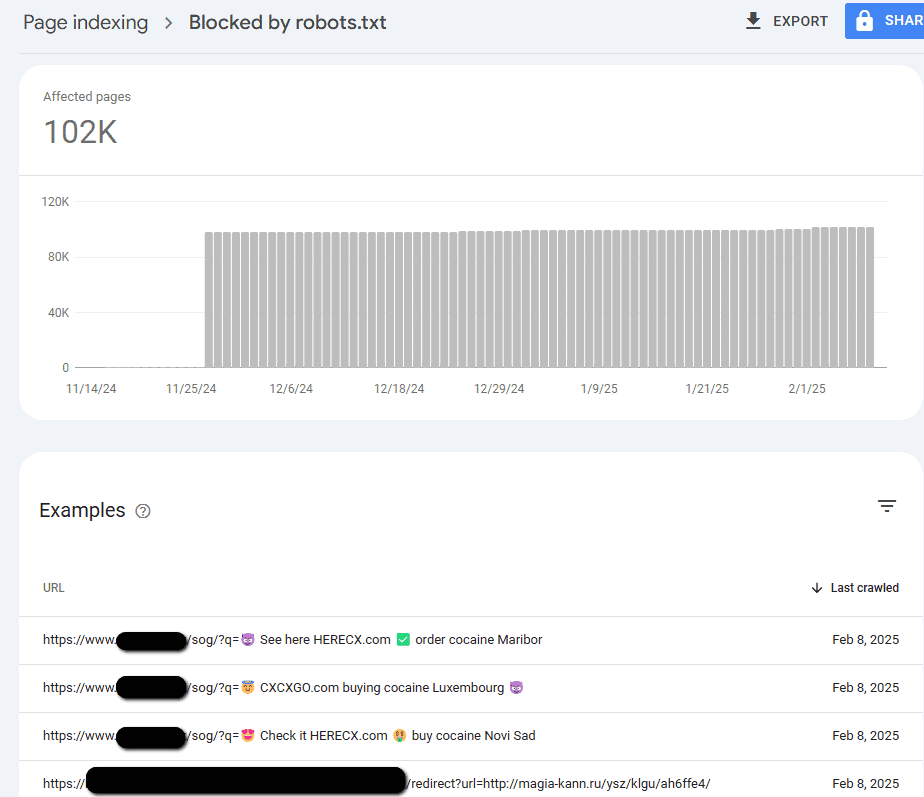
След това тези URL адреси се проучват от екипа и те наистина се оказват нежелани. Специалистите копират няколко от примерните URL адреси и ги вмъкват в инструмента за проверка на GSC. Резултатите ги изненадват, защото виждат, че URL адресите са индексирани!
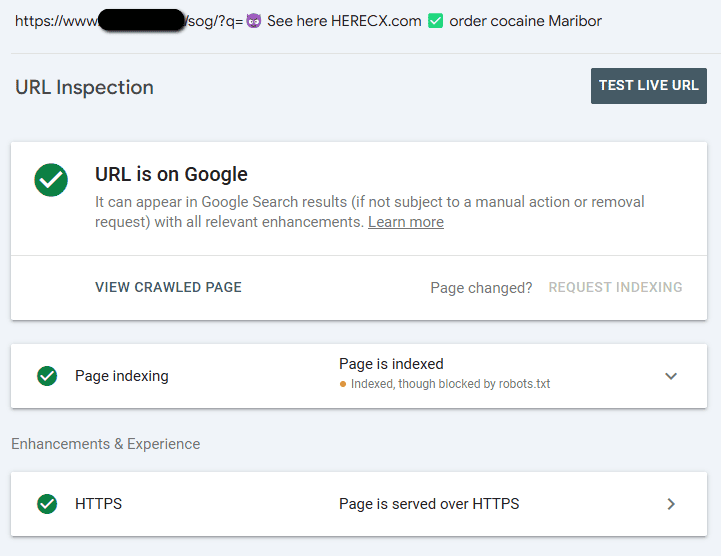
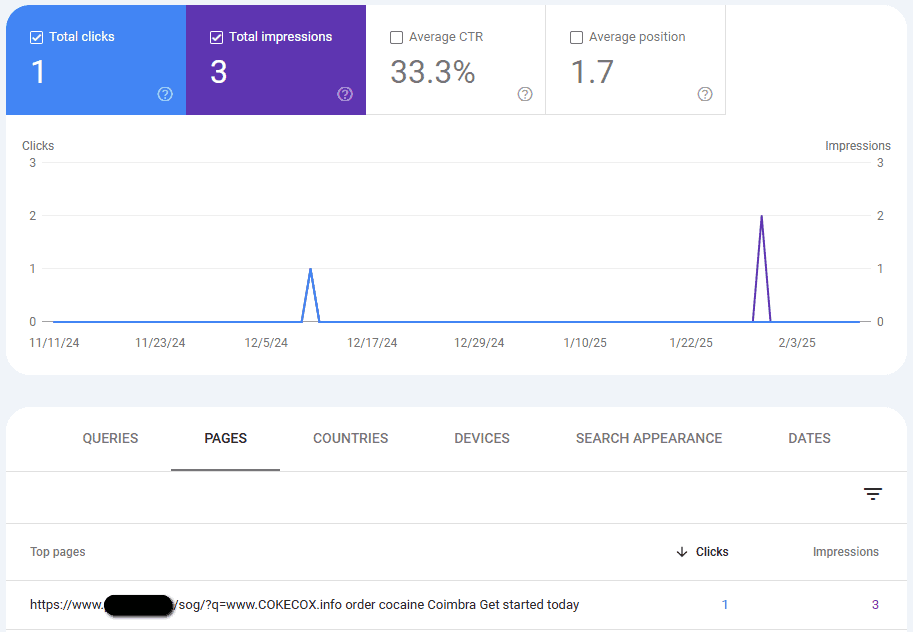
Преди да изпаднат в паника, те правят „тест“, като търсят URL адресите в данните за ефективност в опит да докажат, че трябва да е грешка, че GSC докладва URL адресите като индексирани. Ако URL адресите нямат данни за ефективност, това със сигурност трябва да е грешка!
Въпреки това, някои от резултатите шокиращо показват както кликвания, така и импресии (макар и с изключително малки числа).
Вместо да изпадне в паника, умният SEO специалист ще направи проучване и ще се опита да разбере проблема.
Измамници се опитват да накарат Googlebot да види обратна връзка или споменаване
Ето защо се случва това:
Измамниците се опитват да се възползват от динамичните страници с резултати от търсенето, динамични страници за грешки и подобни динамични страници, които връщат информация на потребителя въз основа на това, което URL адресът показва – както се вижда на снимката по-долу.
![URL адресът съдържа низ за търсене, който след това се повтаря на страницата обратно към потребителя: В този случай низът за търсене е „Click this link --> [URL]“.](https://seoconsult.bg/wp-content/uploads/2025/03/1739350066956.png)
Измамниците се надяват, че такива видове динамични страници на авторитетни уебсайтове не са блокирани в robots.txt и че Google ще открие и обходи тези страници – в идеалния случай получавайки работеща връзка или „просто“ споменаване, видяно от Googlebot.
Фактът, че страниците са динамични означава, че можете да използвате една и съща страница, за да генерирате безкрайни вариации, ако просто „извикате“ страницата с различни параметри в URL адреса.
Интересното в този метод е, че за да работи, той изисква спам мрежата да генерира (обикновено dofollow) връзки към „жертвата-сайт“, за да може Google да улови лошия URL адрес, който се опитва да манипулира динамичната страница.
Защо това не е проблем (когато блокирате в robots.txt):
- Google Search Console докладва, че URL адресите са правилно блокирани от robots.txt
- Robots.txt САМО предотвратява обхождането – не се съхраняват/индексират никакви сигнали от страницата. НО откритите URL адреси все още се съхраняват в индекса. Това е частта, в която повечето SEO специалисти се объркват, затова правете разликата между robots.txt и noindex.
- Тъй като само URL адресът се запазва в индекса, няма загубен краулинг бюджет и Google не вижда (потенциално) спам съдържанието на страницата с резултати от търсенето на уебсайта, защото страницата никога не се обхожда.
- 100 000 URL адреса определено са дразнещи за гледане в отчета на GSC, но те нямат последствия. Google просто ви предупреждава: „Знам за този URL адрес, защото към него сочат връзки – но не знам какво съдържа“.
- Фактът, че URL адресът е индексиран без съдържание означава, че в действителност е невъзможно URL адресът да се класира за каквото и да е нормално търсене. Обаче URL адресът все още може да бъде показан за изключително специфични търсения в Google. Разбира се, нито един нормален потребител никога не би създал такава заявка за търсене, затова данните за ефективност на импресиите и кликванията са толкова ниски (най-вероятно тези данни са генерирани от спам мрежата или SEO специалисти, които проучват в Google).
SEO специалистите твърдят, че трябва да поставите noindex на тези динамични страници (като страницата с резултати от търсенето), за да премахнете тези 100,000 URL адреса. Но, за да работи това е необходимо да премахнете блокирането на страницата с резултати от търсенето в robots.txt.
Препоръка
Направете бърза валидация в GSC, където проверявате както отчета „Индексирани страници“, така и другите отчети за страници „Не индексирани“. Ако някой от тези отчети показва внезапни увеличения, които съвпадат с проблема с лошите URL адреси, може да имате някои URL адреси, които не са „уловени“ от вашия robots.txt. В този случай коригирайте вашия robots.txt, за да блокирате всички динамични страници, които измамниците се опитват да манипулират.
Ако все още нямате този проблем, тогава се уверете, че сте настроили robots.txt да блокира обхождането на вашите динамични страници.
Докато блокирате правилно в robots.txt, няма SEO последствия от този „проблем“ – освен дразнещите данни, показвани в Google Search Console. Ако вече сте настроили блокиранията правилно, това означава, че не е необходимо да предприемате никакви допълнителни действия.
Колкото по-голям уебсайт управлявате или колкото по-голям е вашият бранд, толкова по-голям е рискът да бъдете ударени от тези „измамни атаки“.
Източник: linkedin.com



