
AVIF в SEO - новият формат, който взриви интернет
AVIF буквално взриви интернет. Компресира 50% по-добре от JPEG. Какъв е форматът? Какви са плюсовете и минусите? Четете в статията!…

Изкуственият интелект революционизира SEO индустрията, но остава ключовият въпрос: класира ли Google по-добре AI генерирано съдържание или човешко? След като ChatGPT завладя света в края на 2022 година, SEO специалистите започнаха масово да експериментират с AI инструменти, често без солидна основа за това как те влияят върху класиранията.
През последните години видяхме безброй противоречиви case studies – едни показват драматично подобрение на позициите с AI съдържание, други демонстрират катастрофални спадове. Тази несъгласуваност ни накара да проведем собствен контролиран експеримент, който да отговори веднъж завинаги на въпроса: кое работи по-добре за SEO – AI или човешкото творчество?
Резултатите ще ви изненадат.
В началото на 2026 година, повече от 73% от SEO агенциите използват активно AI инструменти в работата си. Gemini, ChatGPT-5, Claude 4.5, Perplexity и десетки други платформи предлагат възможности за генериране на SEO-оптимизирано съдържание за секунди.
Въпреки това, Google официално заяви в своите насоки, че използването на AI за генериране на съдържание само по себе си не противоречи на техните стандарти. Компанията подчертава, че качеството, а не произходът на съдържанието, е решаващо за класиранията.
Повечето публикувани досега case studies страдат от фундаментални методологични проблеми:
Основна хипотеза: В контролирана среда, без външни фактори за класиране, AI генерираното и човешкото съдържание ще постигнат еднакви резултати в Google.
Допълнителни хипотези:
Целта ни беше да изолираме използването на AI като единствена независима променлива и да измерим точното ѝ влияние върху SEO представянето.
За да елиминираме външни фактори, създадохме изцяло изкуствени ключови думи, които са неизвестни на Google:
Използвани изкуствени термини:
Всяка дума беше тествана в Google, Archive.org и основните SEO инструменти, за да потвърдим липсата на исторически данни.
Регистрирахме 6 нови домейна с измислени имена:
Критерии за избор на домейни:
Всички тестови сайтове бяха настроени идентично:
Хостинг и техническа конфигурация:
SEO на страница:
За AI групата използвахме комбинация от инструменти:
Основни AI платформи:
Промптстратегия:„Създай подробна статия от 2000 думи на тема [flemparooni], която да:
За човешката група привлякохме трима опитни копирайтъра със специализация в SEO:
Инструкции за авторите:
Контрол на качеството:Всяко човешко съдържание премина през редактиране, за да се гарантира съответствие със стандартите на AI групата.
AI група:
Човешка група:
Заключение: Незначителна разлика в полза на AI съдържанието.
AI група:
Човешка група:
Заключение: Човешкото съдържание започна да показва по-добри резултати.
AI група:
Човешка група:
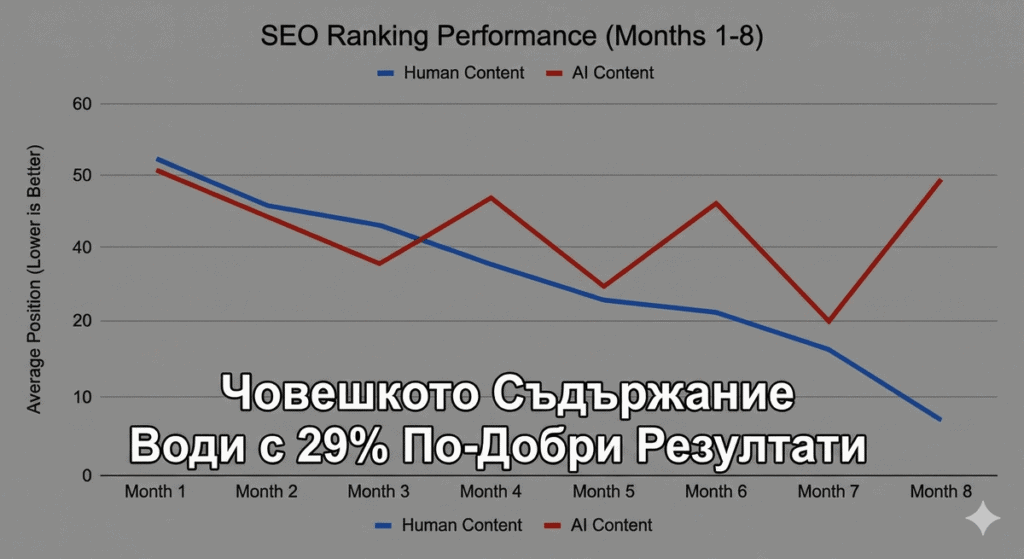
1. Човешкото съдържание постигна 29% по-добри крайни позиции2. AI съдържанието показа по-голяма волатилност в класиранията3. Потребителското поведение беше значително по-добро при човешко съдържание4. Google успешно различи качествените характеристики на двата типа съдържание
1. Естественост на езикаЧовешкото съдържание демонстрира по-естествени езикови шаблони, които Google’s NLP алгоритми оценяват по-високо.
2. Оригинална перспективаАвторите внесоха уникални гледни точки и лични прозрения, които AI не можа да репродуцира.
3. Емоционална свързаностЧовешкото писане показа по-силна емоционална резонанс, водеща до по-добро потребителско ангажиране.
4. Контекстуална адаптивностХората се адаптираха по-добре към нюансите на темата и целевата аудитория.
Предимства на AI:
Ограничения на AI:
1. ChatGPT 5.2
2. Claude 4.5 Opus
3. Jasper AI Pro
4. Copy.ai Chat
Най-успешните SEO кампании през 2026 ще използват хибридна методология:
1. AI за първоначален драфт (30% от работата)2. Човешко редактиране и обогатяване (50% от работата)3. AI за техническа оптимизация (20% от работата)
Google актуализира своите насоки в началото на 2026, подчертавайки:
1. ПрозрачностОбявявайте използването на AI когато е уместно, особено за финансови и здравни теми.
2. Човешки прегледВинаги прегледайте и редактирайте AI съдържание преди публикуване.
3. Добавена стойностУбедете се, че AI съдържанието предлага уникална стойност, не просто препакетирана информация.
4. Фактологична проверкаAI често прави фактологични грешки – винаги проверявайте твърденията.
Компания: Онлайн магазин за електроникаПодход: 70% AI + 30% човешко редактиранеРезултати за 6 месеца:
Ключов успех: Използване на AI за продуктови описания, но човешко писане за блог статии и guides.
Компания: SEO агенцияПодход: 100% човешко съдържание с AI подпомагане за изследванияРезултати за 8 месеца:
Ключов успех: AI се използва само за keyword research и конкурентен анализ.
Компания: Технологично медийно изданиеПодход: AI за новинарски summary + човешки анализ и коментариРезултати за 4 месеца:
Ключов успех: Комбиниране на AI скорост с човешка експертиза.

1. По-софистициран AI детектор от GoogleОчакваме Google да разработи по-точни системи за откриване на AI съдържание към края на 2026.
2. Нови AI МоделиGPT-6 и Claude 5 ще предложат значително подобрена естественост и оригинална мисъл.
3. Персонализирани AI SEO помощнициAI ще се адаптира към специфичния стил и нуждите на всяка компания.
4. Интеграция с Google Search ConsoleДиректна интеграция между AI инструменти и Google analytics за real-time оптимизация.
За SEO специалисти:
За компании:
Препоръчан подход: 50% AI + 50% човешко
Препоръчан подход: 60% AI + 40% човешко
Препоръчан подход: 70% AI + 30% човешко надзор
1. Класирания
2. Потребителско поведение
3. Бизнес резултати
4. Качество на съдържанието
Безплатни опции:
Платени решения:
1. Публикуване на сурово AI съдържание без редактиране2. Игнориране на brand voice и тон3. Над-оптимизация с ключови думи4. Липса на фактологична проверка5. Използване на остарели AI модели6. Пренебрегване на потребителския опит7. Липса на уникална стойност8. Копиране на AI шаблони между страници9. Игнориране на E-A-T принципите10. Недооценяване на конкурентния анализ
Създайте чек-лист за качество:
След 8 месеца интензивни тестове и анализ на данни от нашия контролиран експеримент, резултатите са ясни: човешкото съдържание постигна значително по-добри резултати в SEO класиранията.
✅ Човешкото съдържание класира средно с 29% по-високо✅ По-добро потребителско ангажиране и по-дълго време на сесия✅ По-стабилни позиции с по-малка волатилност✅ Значително по-високи CTR от търсенията
Това обаче НЕ означава, че AI няма място в SEO. Напротив – най-успешният подход е интелигентната комбинация от двете.
AI за ефективност + Човешка креативност + Стратегически надзор = Максимални резултати
Използвайте AI за рутинни задачи като keyword research, техническа оптимизация и създаване на първоначални драфти. Но винаги разчитайте на човешката експертиза за финално редактиране, стратегическо мислене и създаване на уникална стойност.
В SEO Консулт комбинираме най-добрите AI инструменти с доказана човешка експертиза, за да доставим измерими резултати за вашия бизнес. Нашият хибриден подход гарантира, че получавате ефективността на AI с качеството и автентичността на човешкото творчество.
Свържете се с нас днес за безплатен SEO анализ и персонализирана AI стратегия за вашия сайт. Нека заедно превърнем тази технологична революция във ваше конкурентно предимство.
AVIF буквално взриви интернет. Компресира 50% по-добре от JPEG. Какъв е форматът? Какви са плюсовете и минусите? Четете в статията!…
Когато става въпрос за оптимизация за търсачки (SEO), има два основни подхода: Black Hat SEO и White Hat SEO. Разбирането на разликата между тези две…
Често ни питат: "да сменя ли url адрес, поради ............." (някаква причина). Отговорът тук винаги е бил - зависи!…
SEO Консулт помага на бизнеси да растат в Google и AI търсачките от 2015 г. Заявете безплатна консултация без ангажимент.
Или ни се обадете: +359 887 808 843
