
Търсачките не „внасят“ веднага нови страници в своите бази данни. Процесът на индексиране може да отнеме седмици или месеци. И това е пряка пречка за SEO. Затова е важно да знаем, какво е „обхождащ бюджет“ и защо той трябва да бъде оптимизиран.
Какво е обхождащ бюджет?
Бюджетът за обхождане (или т.нат. краулинг бюджет) е броят на страниците, които един робот за търсене може да обходи в даден сайт. Още по-точно казано – това е броят на актуализираните страници, които един робот за търсене може да индексира в даден период от време.

Това число може да варира от малко до голямо. Важно е да се разбере, че тази граница е различна за всеки сайт. Популярният „стар“ сайт постоянно се обхожда, а при новите се забелязва известно забавяне във времето.
Причината е проста: ресурсите на търсачките не са неограничени. Никакви центрове за данни не са достатъчни, за да проследят незабавно всички промени в милиарди сайтове по света. Особено когато става въпрос за безполезни и непопулярни ресурси. Ако ботът обхожда страници с ниско качество, бюджетът се намалява. А с него и успеха.
Защо това е важно изобщо – роботът сканира определен брой страници и той може неправилно да обходи URL адреси, които изобщо не са ви необходими. Възможно ли е да се повлияе на търсещите машини за увеличаване на този брой? До известна степен да. По-долу ще разгледаме основните средства за оптимизиране на лимита на обхождане на страници на сайтове чрез роботите за търсене.
Как работи обхождането?
Роботът за търсене получава списък с URL адреси за обхождане на сайта и периодично го обхожда. Как се формира този списък? Състои се от:
- вътрешни връзки към сайта, включително инструменти за навигация
- карта на сайта във формат XML (sitemap.xml)
- външни връзки
За да разбере дали URL адресът може да бъде включен в списъка за обхождане, роботът за търсене периодично проверява файла robots.txt, съдържащ забраните и разрешенията. Ако URL адресът не е забранен, той ще попадне в списъка за обхождане. Но имайте предвид: директивите от списъка robots.txt не са команда на робота. Те са просто препоръка. И в някои случаи забранен URL адрес пак може да попадне в индекса. Роботът решава, че това е някаква грешка, и ще продължи да обхожда страницата, а Google ще ви покаже в конзолата „индексирани въпреки забраната“.
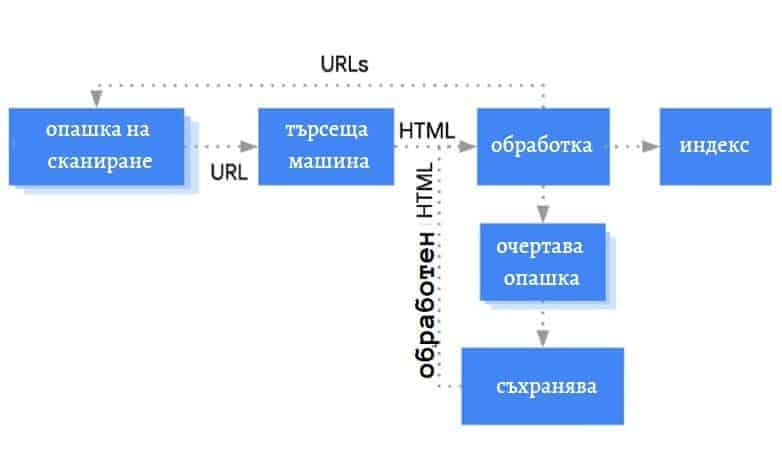
Процесът обхождащите роботи за Google – създава списък с URL адреси и ги сортира по приоритет. След което стартира сканиране на списъка, отгоре надолу.
Как се определят приоритетите?
На първо място, Google взема предвид PageRank-а на страницата. Допълнителни фактори включват картата на сайта, линкове и др. След като роботът обходи URL адреса и анализира съдържанието му, той добавя новите адреси в списъка за обхождане, за да ги обходи по-късно или в някакъв следващ момент. Няма точен начин да се направи списък с причини, поради които роботът за търсене ще обходи или не даден URL адрес.
Как да идентифицираме проблем с краулинг бюджета?
Ако роботът за търсене намери много връзки на вашия сайт и ви даде голям лимит, тогава всичко е наред. Но какво ще стане, ако сайтът ви е стотици хиляди страници и лимитът е малък? В този случай ще трябва да изчакате месеци, докато търсачката забележи всички промени по страниците.
За да разберете дали имате проблем с обхождащия бюджет, можете да направите следното:
- Определете колко страници на вашия сайт трябва да бъдат индексирани (те не са затворени от мета маркера NOINDEX и не са забранени в robots.txt)
- Отидете Google Search Console. Сравнете броя на индексираните страници с броя на страниците на вашия сайт
- Използвайте инструментите за статистика на обхождането или статистически данни за обхождане в зависимост от търсачката
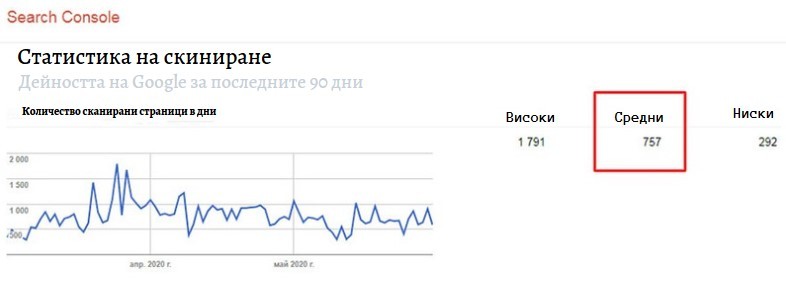
- Разделете броя на страниците на средния брой обходени страници на ден. Ако резултатът е 10 пъти повече от страниците, сканирани от търсачката на ден, тогава определено трябва да помислите за оптимизиране на лимита на обхождане. Ако числото е по-малко от 3, значи всичко е наред.
Как да увеличите бюджета си за сканиране?
Тук има много точки, като може да започнете от най-простите и постепенно да усложнявате. Всички тези методи са ефективни.
Общият принцип, който трябва да научите е – всяка индексирана по-рано страница, която роботът за търсене не може да обходи няколко пъти подред, се изхвърля от индекса. Това се отнася за страници, които не са достъпни по технически причини (например грешки тип 500) и страници, които умишлено са затворени от индексиране, например, използвайки маркера NOINDEX.
В Google такъв процес на деиндексация е дълъг, отнема месеци с периодични проверки, за да се види дали страницата е станала достъпна.
Отървете се от грешки
За нормално конфигуриран сайт има само два типа валидни отговори на сървъра: 200 (OK) и 301 (постоянно пренасочване). Освен това 200 OK трябва значително да надвишават тези с 301. Всичко останало изисква внимателно обмисляне и коригиране. Затова:
- Ако по някаква причина, вместо код 301 за постоянно пренасочване (301 redirect), сте използвали временен 302, роботът ще ви разбере буквално така: съдържанието временно не е достъпно, ние не го изтриваме и периодично проверяваме как е. Това си е чиста загуба на бюджет
- Вторият пример е използването на код 404 (не намерена страница) вместо код 410 (изтрита за постоянно). Логиката е проста: веднъж изтрита, я изхвърляме от индекса и я забравяме. А 404 означава, че ако не е намерил страницата при това обхождане, може да я намери следващия път. Отново източване на бюджета, ако страницата е наистина изтрита и вече няма да се показва. В същото време страницата даваща 404, може да събере т.нар. page wieght, което в този случай се губи. Най-разумното тук: направете списък от 404 и анализирайте дали е възможно да конфигурирате пренасочване към еквивалентна или подобна страница.
- Най-неприятно е, ако сървърът редовно дава грешки 500. Това е ясен знак за ресурс с лошо качество, който роботът ще посещава все по-малко и все по-малко за сканиране.
Ако видите това в отчетите или резултатите на SiteAnalyzer, Screaming Frog SEO Spider или техните аналози, разберете причините и вземете спешни мерки.
Отървете се от дублирани и счупени връзки
 Индексът не трябва да включва т.нар. служебни страници, потребителски страници, които дублират други страници, страници с филтри, сравнения на продукти, страници с UTM тагове, параметри и идентификационни номера на сесия, страници с чернови. Затворете ги от индексиране с robots.txt и таг noindex.
Индексът не трябва да включва т.нар. служебни страници, потребителски страници, които дублират други страници, страници с филтри, сравнения на продукти, страници с UTM тагове, параметри и идентификационни номера на сесия, страници с чернови. Затворете ги от индексиране с robots.txt и таг noindex.
Проблемът с дублирането е особено често срещан в сайтовете за електронна търговия. Едно и също съдържание е достъпно на различни адреси. Говорим за сортиране, филтриране, вътрешни страници за търсене и т.н. Често по време на одита можете да видите, че страниците за сравнение на продуктите и потребителските сесии по принцип попадат в индекса.
Основно правило: запазете само една версия на URL адреса!
В някои случаи е просто невъзможно да затворите дублиращата страница от робота чисто технически. В този случай използвайте canonical таг, който обяснява на робота коя страница трябва да бъде в индекса и коя може да бъде игнорирана. В този случай canonical действа като soft 301 пренасочване.
Пример за такъв случай: продуктова страница попада в две различни категории продукти и се показва с различни URL адреси. Оказва се, че имате две еднакви страници с различни адреси. Търсачките „слепват“ такива страници и изхвърлят едната от индекса. И това може да се повтори отново и отново. За да избегнете подобно нещо и да не губите краулинг бюджет, настройте canonical, ако CMS (системата за управление на съдържанието) на сайта не предлага по-добро решение.
Друг вариант: използвайте мета тага NOINDEX.
За да се отървете от дублиранията напълно, са необходими по-радикални мерки от директивите за ботовете. Оптимално оценете способността за премахване на дублирано съдържание.
Пример: варианти на един и същ продукт, различаващи се по минимални параметри и свойства (цвят, размер и т.н., ако те нямат значение за купувача).
Намалете пренасочванията
Първото нещо, с което започва техническия одит на даден сайт, е проверка на пренасочванията към началната страница. Достъпът до страницата може да се осъществява чрез HTTP или HTTPS, както и със и без WWW. Това са дубликати и в този случай търсачката може да счита някоя от тези версии за основно огледало и вие ще загубите контрол и бюджет за обхождане. Затова е наложително да конфигурирате 301 редирект пренасочване към избраната от вас версия.
Важно! Трябва да се уверите, че се използва едно пренасочване. С неправилни настройки за пренасочване можете да получите верига от две или три пренасочвания. Това е лошо и ето защо: роботът за търсене вижда новите URL адреси и ги добавя към своя план за обхождане. Но това не означава, че той ще отиде на тези URL адреси в момента. И колкото по-дълга е веригата от пренасочвания, толкова по-дълъг е процесът. Сканирането се забавя.
Друг проблем с излишните пренасочвания е т.нар. тегло на връзката. Всяко пренасочване го намалява, така че изграждането на връзки работи по-малко ефективно. Разбира се, трябва да проверите за двойни пренасочвания не само към главната страница. Ако по време на анализа на посещенията на страницата видите проблемни точки – не забравяйте да проверите пренасочванията.
Персонализирайте картата на сайта (sitemap.xml)
Тази карта трябва да съдържа пълен списък от страници, които трябва да бъдат в индекса. Изключително важно е! Търсачките го използват за навигиране и до известна степен за получаване на указания за приоритетите. Sitemap.xml може да съдържа информация за датата на създаване, последната промяна, приоритета, който сте задали по важност, честотата на обхождане и т.н.
Не е нужно обаче да мислите, че роботът задължително ще вземе предвид вашите инструкции. Всъщност можете да разчитате само на робота, за да видите вашия списък с URL адреси за обхождане и да го използвате рано или късно. Всичко останало обикновено се игнорира, за да се избегне манипулация.
Не всеки CMS ви позволява да създадете карта на сайта в съответствие с вашите планове и много „боклук“ може да стигне до там. По-лошото е, че някои CMS не знаят как да създават такива карти на сайта. В такива случаи се използват плъгини на трети страни или дори ръчно изтегляне на карта на сайта, формирана от някакъв софтуер или външна услуга.
Някои експерти препоръчват да премахнете дори желаните URL адреси от картата на сайта, след като страниците са индексирани. Не правете това, защото това също може да повлияе зле на бюджета на обхождането. Периодично проверявайте sitеmap.xml – не трябва да има изтрити страници, URL адреси с пренасочвания и грешки.
Проектирайте структурата на сайта
Това е може би една от най-трудните за изпълнение задачи: цялостното преструктуриране на съществуващ сайт не е лесна задача. Разбира се, по-лесно е да го направите още на етапа на разработка.
Структурата на сайта, до която всяка страница е достъпна не повече от 4 кликвания от основната, се счита за плоска. Дълбока структура на сайта – с вмъкване от 5 кликвания от главната страница.
Основният принцип: дълбоките сложни вертикални структури на сайтовете се сканират много по-сложно от плоските структури. Да, и посетителите трябва сериозно да се потрудят докато намерят интересуващото ги съдържание. И ако добавите неефективна навигация към това и дори за мобилни устройства, тогава имате глобален проблем.
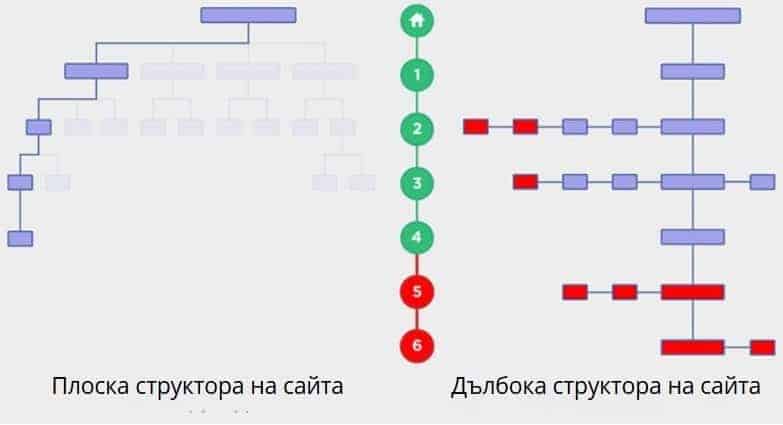
Използвайте принципите на плоската структура на сайта, така че важните страници да са възможно най-близо до главната страница. Хоризонталната, „плоска“ структура е много по-предпочитана от вертикалната.
Не бива обаче да се мисли, че една абсолютно плоска структура, лишена от групиране на страници в категории, ще даде предимство само поради достъпността. Необходимо е да се създаде структура, съчетаваща достъпността и логическата йерархия. Този въпрос обаче е твърде глобален, за да бъде разгледан в рамките на тази статия.
За да оптимизирате структурата, може да са ви необходими доста нетривиални методи, освен това да надхвърлите чисто техническoто SEO. На първо място, струва си да започнете с визуализирането на съществуващата структура: много инструменти, използвани за одит на сайта, могат да направят това. На този етап можете поне да направите малки корекции за визуална оценка на несъвършенството на структурата на сайта.
За глобални промени, започнете със семантиката и групирането на заявките. Вижте какво можете да свържете, комбинирате, да преминете на по-високо ниво. И нещо вероятно си струва да се премахне напълно.
Персонализирайте заявката Last-Modified (последно променен)
Това е важен технически параметър, който разработчиците на уебсайтове и системните администратори почти винаги игнорират. И не всеки специалист по SEO разбира важността на подобен отговор на сървъра. И напразно.
Last-Modified се използва за няколко цели:
- намаляване на натоварването на сървъра;
- ускорение индексирането на страниците
- увеличаване на скоростта на изтегляне.
Колкото по-голям е вашият сайт и колкото по-често актуализирате съдържанието, толкова по-важно е правилното конфигуриране на такъв отговор на сървъра. Най-често такъв отговор изобщо няма.
Как работи Last-Modified? Робот за търсене или браузър осъществява достъп до конкретен URL адрес, изискващ страница. Ако страницата не се е променила след последното взаимодействие, сървърът връща заглавката „304 Not Modified“. Съответно няма нужда да презареждате съдържание, което вече е в кеша и индекса. Но ако е имало промени, сървърът ще върне 200 ОК и новото съдържание ще бъде изтеглено.
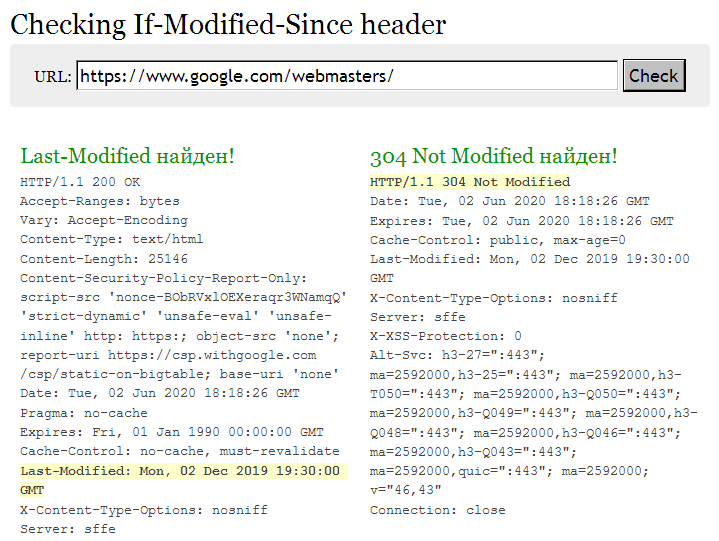
В допълнение към подобряването на ефективността, търсенето ще актуализира датата на съдържанието на страницата. И това е много важно като фактор за класиране, особено в области, свързани с човешкото здраве и финанси (YMYL).
Last-Modified позволява на робота да премахне от списъка на URL адресите онези страници, които не са актуализирани, и да сканира актуализираните, тоест оптимизирани от вас. Вие помагате да зададете приоритети и да спестите обхождащ бюджет.
За проверка можете да използвате last-modified.com или неговите аналози.
„Кръгови и висящи“ връзки и изолирани страници
 Тези два типа грешки са пряко свързани с развитието на вътрешните линкове и създават проблеми с обхождането и индексирането. За щастие – много малък.
Тези два типа грешки са пряко свързани с развитието на вътрешните линкове и създават проблеми с обхождането и индексирането. За щастие – много малък.
Кръгова връзка – връзка на страницата към себе си. Най-простият вариант е активен breadcrumb, която обозначава самата страница. Най-добре е да премахнете активната връзка от нея, така че да работи само като навигация, показвайки на посетителя къде точно се намира в момента. Но можете напълно да го премахнете, използваемостта няма да страда от това.
Висяща връзка (dead end) е страница без изходящи връзки. Тя приема някакъв ранг, но не го дава никъде. Един вид задънена улица за робота, който няма къде да отиде от страницата. Най-често такива страници не представляват сериозен проблем, но трябва да анализирате естеството на такава страница и, ако е възможно, да направите корекции.
Значително голям проблем са изолираните страници, към които не води нито един линк. За щастие това е рядкост в съвременните CMS. Например, по някаква причина страницата не попада в списъците с категории, не е в навигацията на сайта или още по-лошо – сайтът е хакнат и нападателите публикуват съдържанието си там за да печелят външни връзки. Преценете дали тази страница изобщо е необходима и ако трябва да бъде индексирана, отстранете проблема.
Насърчете роботите да обхождат
По някакъв начин можете да повлияете на процесите на индексиране на страници ръчно, въпреки че тук говорим, по-скоро, не за оптимизиране на обхождането. Има няколко начина да насърчите роботите.
Използвайте обхождане в панели за уеб администратори. Google ви позволява ръчно да „захранвате“ системата с променени или нови URL адреси и да ускорите процеса на обхождане. Използвайте ги! Основният недостатък е дългия процес в Google.
Правете репост в социалните мрежи
Да, все още работи. Изберете социална мрежа, която роботите сканират добре и постоянно наблюдават, и пуснете връзка там. Обикновено се използва Facebook или Twitter. Експериментирайте.
Услуги за индексиране
Такива услуги ви позволяват да подадете неограничен (обикновено) брой URL адреси, изчакайте малко – и за около една седмица можете да добавите няколко хиляди нови URL адреси в индекса с тази маневра, независимо от бюджета за обхождане. Проблемът е, че читавите такива услуги са платени.
Проучвайте сървърните логове
Проучването на сървърните логове ще ви даде максимална информация за маршрутите на ботовете и графика на техните обикаляния. Достъпът до тези файлове обаче не винаги е възможен, той се определя от вида на хостинга.
Ако нямате умения за администриране на сървър, съдържанието на лога със сигурност ще ви изплаши. Прекалено много данни и най-вече ненужни за вас. Ако сайтът е малък, тогава можете да работите с регистрационни файлове дори в Notepad ++. Но опит за отваряне на дневника на голям онлайн магазин ще „постави“ вашия компютър на рамото. В този случай е по-добре да използвате подходящ софтуер, който ви позволява да сортирате и филтрирате данни.
За анализ можете да използвате софтуери като GamutLogViewer или Screaming Frog Log File Analyzer или външни услуги като splunk.com. Но външните услуги обикновено са проектирани за големи количества данни и са скъпи.
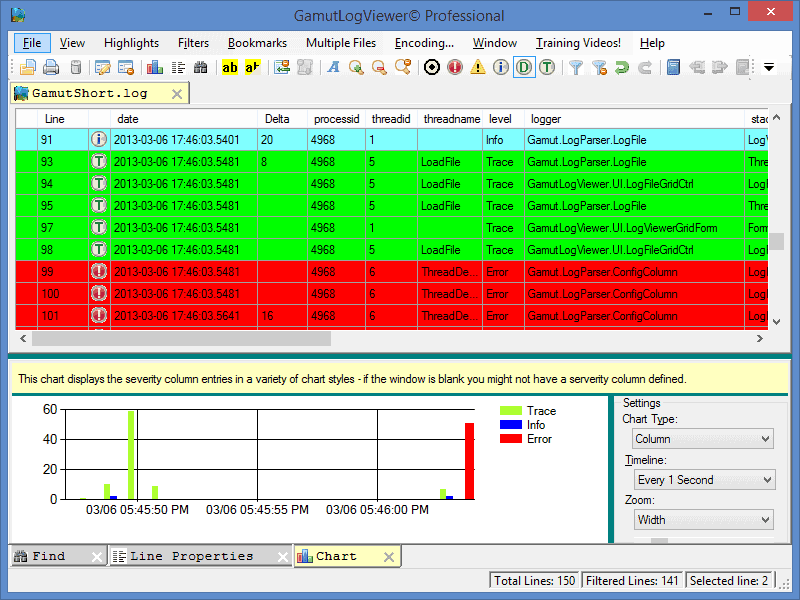
Има и проблеми: не всеки GoogleBot, който сте намерили в регистрационните файлове, наистина е GoogleBot. Затова обърнете внимание на IP бота и го минете през WHOIS, за да филтрирате фалшификатите. Вашата задача е да обработвате данни за достатъчно голям период от време (месец е оптималния) и да намерите някои модели. Като например:
- Колко често влиза ботът
- Кои URL адреси се посещават най-често
- Кои URL адреси обикновено се игнорират
- Отговаря ли на грешки и кои
- Обхожда ли картата на сайта
- Кои категории консумират най-много ресурси
След като получите такива данни, ще си отговорите на въпроса дали ботът оценява целевите ви страници, какво смята за лошо качество и какво предпочита. Например, можете да разберете, че роботът предпочита информационен раздел, направен като допълнение към магазина. А причината е, че информационният раздел получава много повече вътрешни връзки, което означава приоритет за робота.
Заключение
Оптимизирането на crawling бюджете е една от най-важните части на техническото SEO, тъй като твърде малкият бюджет намалява ефективността на оптимизацията. Ако сайтът е технически добре настроен, семантично структуриран и обемите му са малки, тогава не са необходими специални трикове.
Уверете, че 100% от страниците на вашия сайт са съставени от уникално, качествено съдържание. Това не е лесно за сайт с 10k + страници. Но е задължително, ако искате да извлечете максимума от бюджета си за обхождане.



