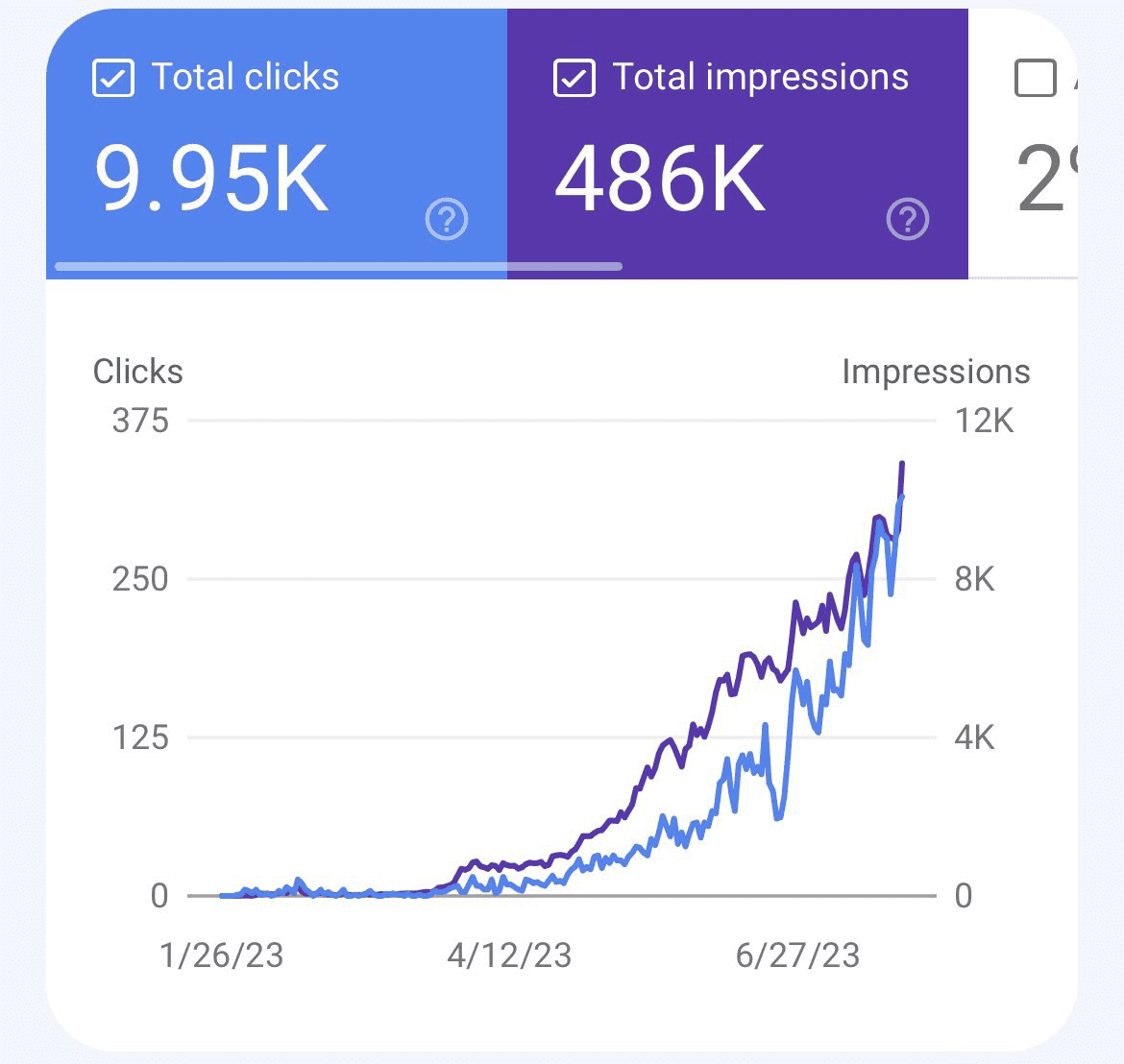
Ударно публикуване на статии в началото е плюс за SEO
Високият първоначален процент на публикуване на съдържание е от огромно значение. От момента, в който Google узнае, че сайтът ви съществува, публикува…
VS се явявва индикатор за противопоставяне. Какво се случва в търсачката, когато се използва конструкцията [ключова фраза] VS?
Как работи алгоритъмът? Как да извлечете полза от тях за сайта?
С какво са особени ключовите фрази с vs? Интент се явява сравнението. Потребителят въвежда ключовата дума и vs, след което очаква списък с различни предложения за нещо подобно от търсачката.

Изключително удобна опция. Причините, поради които използването на фразата за сравнение vs е станала широко използвана в търсенето са следните:
Ефективен е и при намирането на алтернативи. Аналогични ключови фрази няма. Ако въведете versus или or, резултатите ще бъдат по-малко свързани.
Вижте примера с or. Сравняваме bert or с bert vs и резултатът е следният:
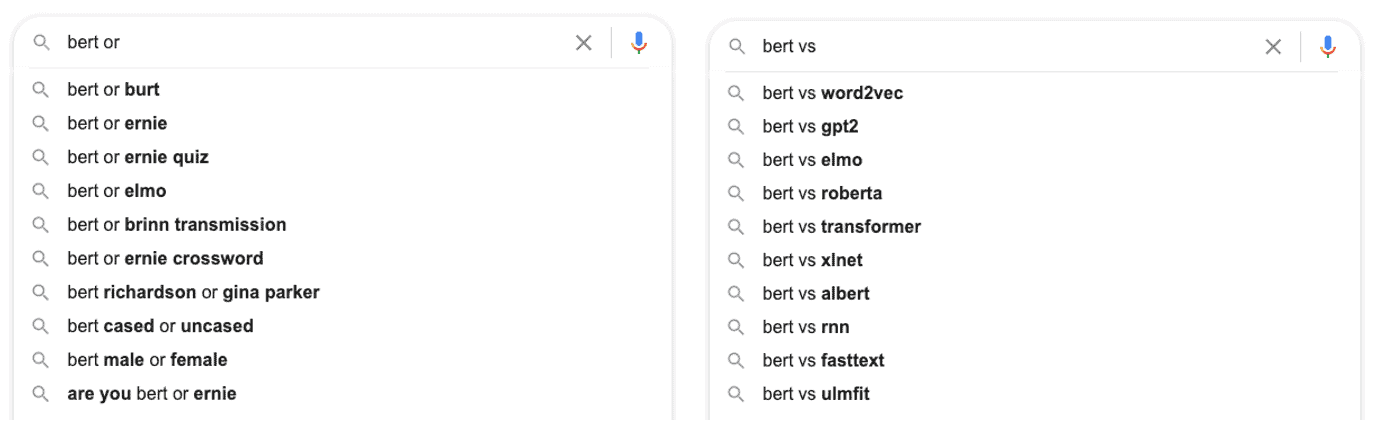
В случай на използване vs, търсачката обработва интента и предоставя списък с алгоритми, които са подобни на Google BERT.
А какво ще се случи, ако:
В резултат използването на подобна методология от оптимизатора дава възможност за сглобяване на семантична структура. Получаваме следното:
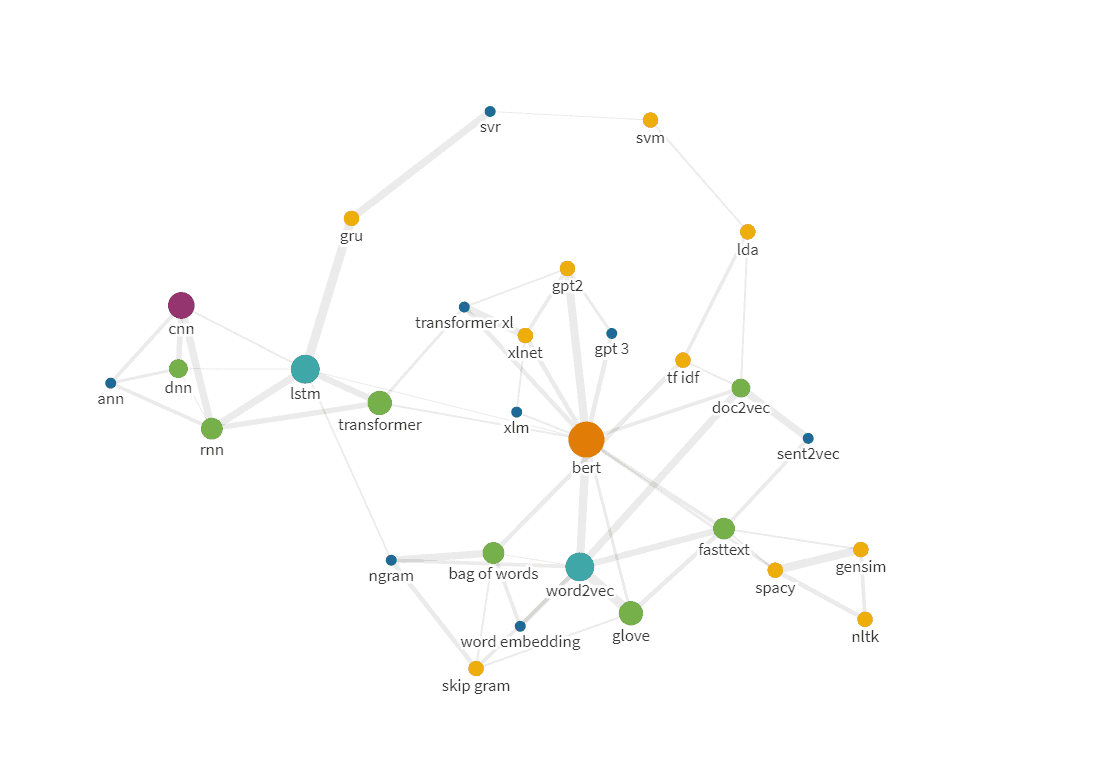
Практическото приложение е широко:
Всички приложения водят до подобрено класиране на страниците в резултатите от търсенето. Например, система от подходящи препоръки може да увеличи фактора Dwell Time /показател, който дава инфо колко дълго потребителят е бил на сайта от момента, в който е щракнал върху него/ и т.н.
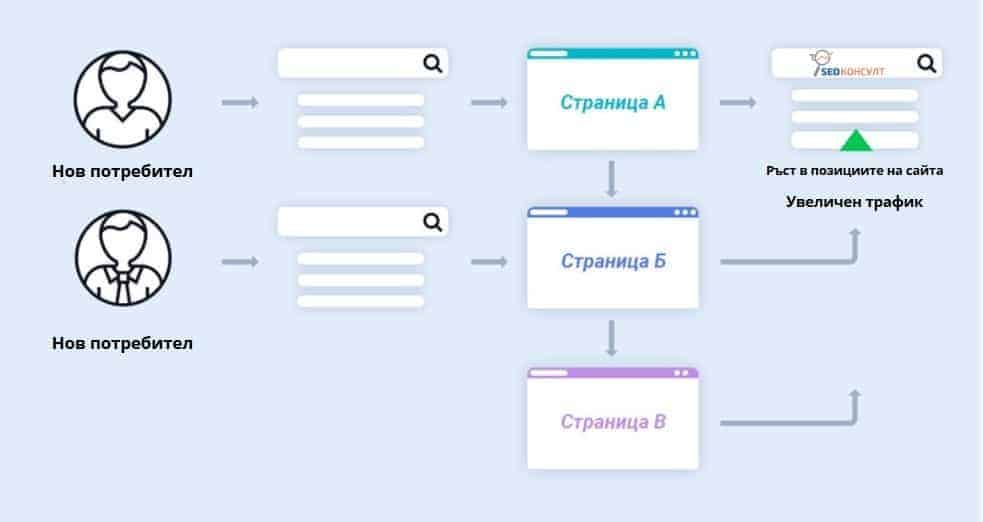
Google има специална връзка за изтегляне на данни с подсказки. Изглежда така: http://suggestqueries.google.com/complete/search?&output=toolbar&gl=us&hl=en&q=[ключова дума]
Параметрите са: • output=toolbar показва, че данните ще бъдат предоставени във формат XML; • gl = us задава кода на държавата (сменяте с bg за България) • hl = us задава езика (сменяте с bg за България) Параметърът q е за ключовата дума
Пример с думата „почивка малдиви“ – http://suggestqueries.google.com/complete/search?&output=toolbar&gl=bg&hl=bg&q=[%D0%BF%D0%BE%D1%87%D0%B8%D0%B2%D0%BA%D0%B0%20%D0%BC%D0%B0%D0%BB%D0%B4%D0%B8%D0%B2%D0%B8]
Резултат:
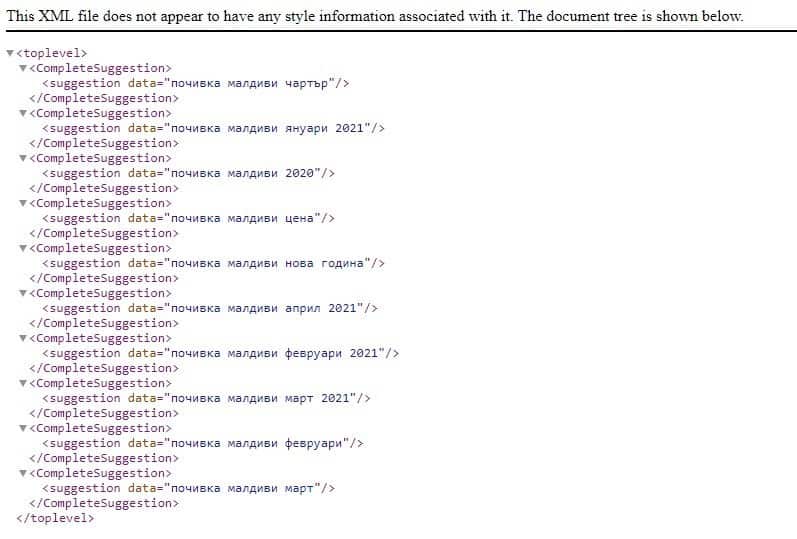
Когато качвате данни, трябва да ги „почистите“. По-добре е да го направите в началото още на етап сканиране. Защо? За да не е чистите голям обем от данни по-късно. Въз основа на практиката е съставен следният списък от правила.
След vs трябва да изтриете резултати, чийто текст:
Резултатът е съвкупност от семантични връзки между множество заявки.
След като анализираме заявките и определим връзките, можем да изградим мрежова графика. Пример за графика:
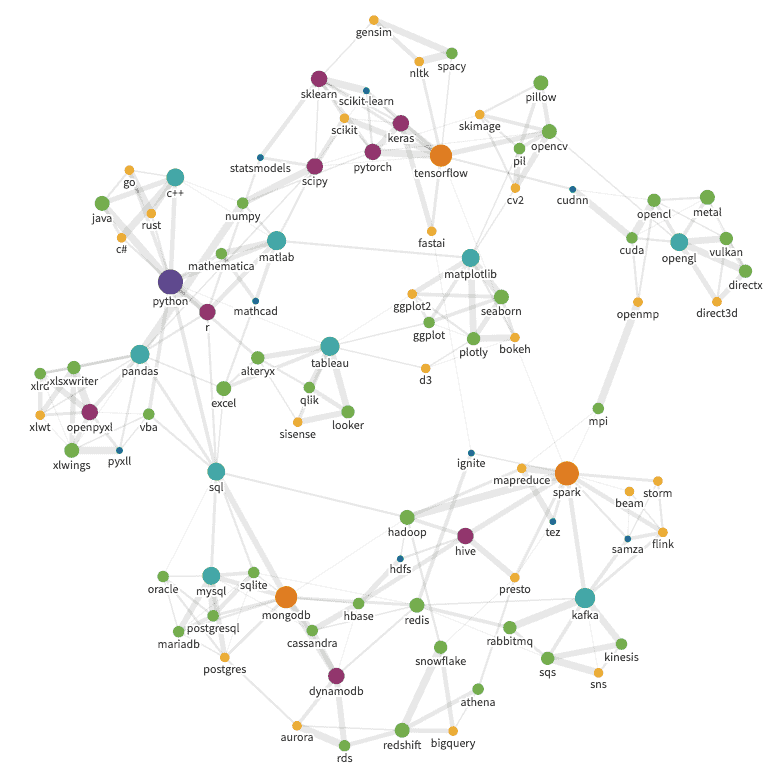
Изображението съдържа повечето основни технологии, за които трябва да знаят онези, които се занимават с изкуствен интелект. Резултатът е логично групиране на много технологии.
Как да направите визуализация? Чрез софтуери. Например, за да създадете горната графика е достатъчно да използвате безплатната електронна таблица на Google и безплатната версия на flourish.studio.
Как да автоматизирате създаването на графики? Например, използвайте пакета Python networkx. Пакетът има специална функция за графики. Името на функцията е ego_graph. За удобство Ви предоставяме готов шаблон с кодове за изграждане на графики:
import networkx as nx
# SAMPLE DATA FORMAT #nodes = [(‘tensorflow’, {‘count’: 13}), # (‘pytorch’, {‘count’: 6}), # (‘keras’, {‘count’: 6}), # (‘scikit’, {‘count’: 2}), # (‘opencv’, {‘count’: 5}), # (‘spark’, {‘count’: 13}), …]
#edges = [(‘pytorch’, ‘tensorflow’, {‘weight’: 10, ‘distance’: 1}), # (‘keras’, ‘tensorflow’, {‘weight’: 9, ‘distance’: 2}), # (‘scikit’, ‘tensorflow’, {‘weight’: 8, ‘distance’: 3}), # (‘opencv’, ‘tensorflow’, {‘weight’: 7, ‘distance’: 4}), # (‘spark’, ‘tensorflow’, {‘weight’: 1, ‘distance’: 10}), …]
#BUILD THE INITIAL FULL GRAPH G=nx.Graph() G.add_nodes_from(nodes) G.add_edges_from(edges)
#BUILD THE EGO GRAPH FOR TENSORFLOW EG = nx.ego_graph(G, ‘tensorflow’, distance = ‘distance’, radius = 22)
#FIND THE 2-CONNECTED SUBGRAPHS subgraphs = nx.algorithms.connectivity.edge_kcomponents.k_edge_subgraphs(EG, k = 3)
#GET THE SUBGRAPH THAT CONTAINS TENSORFLOW for s in subgraphs: if ‘tensorflow’ in s: break pruned_EG = EG.subgraph(s)
ego_nodes = pruned_EG.nodes() ego_edges = pruned_EG.edges()
Какво ще се случи, ако ключовата фраза се отнася за две ниши? Задачата се решава от функцията k_edge_subgraphs. Функцията k_edge_subgraphs намира групи, които не могат да бъдат разделени чрез извършване на k или по-малко действия. От практиката оптималните прагови стойности са k = 2 и k = 3. В резултат графиката ще бъде почистена от излишни неща.
Методология, използваща vs заявки, позволява да се идентифицират семантични структури. Схемата е проста. За да идентифицирате структурата, първо трябва да качите vs данните. След това да съберете всички тематични фрази. Търсачката маркира намерените елементи като близки семантично. Практическото приложение е широко.
Използването на бранд във фраза за ключови думи не е задължително. Методиката също работи с ястия, телевизионни предавания и всичко останало. Връзките са разработени най-добре в сегмента на английския език. Следователно, ако има малко връзки, намерени на друг език, тогава трябва да се използва преводач.
Високият първоначален процент на публикуване на съдържание е от огромно значение. От момента, в който Google узнае, че сайтът ви съществува, публикува…
Научете как да измервате и подобрявате видимостта на вашия сайт в Google. Актуални методи, инструменти и стратегии за 2026 година…
Видимостта на сайта е възможният брой негови импресии за определени теми. Подобрете видимостта му възможно най-много за повече трафик…
SEO Консулт помага на бизнеси да растат в Google и AI търсачките от 2015 г. Заявете безплатна консултация без ангажимент.
Или ни се обадете: +359 887 808 843